Selenium相关
Selenium Web自动化测试与爬虫 系统学习大纲
一、 Selenium 概述与生态
- 1.1 Selenium是什么?
- 定义:一套用于Web应用程序自动化测试和网页交互的工具集。
- 核心组件:Selenium IDE, Selenium WebDriver, Selenium Grid。
- 与Puppeteer、Playwright、Cypress等工具的简要对比。
- 1.2 核心组件详解
- Selenium IDE:浏览器插件,用于录制与回放脚本(主要用于原型和简单脚本生成)。
- Selenium WebDriver:核心,提供了一套与浏览器进行原生交互的API(通过浏览器驱动程序)。
- Selenium Grid:用于分布式测试,支持在多台机器、多种浏览器/操作系统上并行执行测试。
- 1.3 工作原理
- WebDriver API -> 浏览器驱动 (如 chromedriver, geckodriver) -> 真实浏览器。
- JSON Wire Protocol (旧) / W3C WebDriver Protocol (新)。
-
1.4 发展历史
Selenium 版本演进概览
版本 发布时间 核心特点 主要组件/架构 关键更新与影响 Selenium 1.0 2004‑2006 年 基于 JavaScript 注入的早期框架,支持多浏览器但受安全模型限制。 Selenium IDE (Firefox 插件)
Selenium Grid
Selenium RC (Remote Control)• 首创跨浏览器自动化能力。
• 缺点:同源策略限制,难以处理本机事件、文件上传等。Selenium 2.0 2011 年左右 融合 WebDriver,通过浏览器原生 API 直接控制,绕过 JS 沙箱,提升速度与稳定性。 WebDriver (核心)
(Selenium RC 逐渐被替代)• 解决了 RC 的沙箱限制,支持更真实的用户输入模拟。
• 为全面转向 WebDriver 架构奠定基础。Selenium 3.0 2016 年 7 月 移除 Selenium RC,全面拥抱 WebDriver;推动浏览器厂商提供官方驱动,走向标准化。 WebDriver (唯一核心) • 移除 Selenium RC,仅支持 Java 8+。
• Firefox 驱动改为 geckodriver,并支持 Safari、Edge 的官方驱动。Selenium 4.0 2021 年 10 月 完全符合 W3C WebDriver 标准;引入多项现代特性,提升开发体验与分布式测试能力。 WebDriver (W3C 标准)
Selenium Grid (重构)• 相对定位器 (Relative Locators)。
• 集成 Chrome DevTools 协议。
• Grid 重构,支持容器化,内置监控。
• 改进窗口管理、Actions API 等。演进主线:从基于注入的 RC (1.0) → 融合原生控制的 WebDriver (2.0) → 移除RC、推动官方驱动 (3.0) → 全面标准化、增强开发者工具与网格 (4.0)。
二、 环境搭建与第一个脚本
- 2.1 语言与工具选择
- 支持的编程语言:Python (主流)、Java、C#、JavaScript、Ruby。
- 开发环境:PyCharm (Python), IntelliJ IDEA (Java), VS Code 等。
- 2.2 Python 环境搭建 (以Python为例)
- 安装Python。
- 使用
pip安装Selenium库:pip install selenium。 - 安装浏览器驱动:
- ChromeDriver:从官方下载,版本需与Chrome浏览器版本匹配,并添加到系统PATH或指定路径。
- GeckoDriver: for Firefox,建议使用最新版,GeckoDriver通常向下兼容多个 Firefox 版本。
- edgeDriver:Edge WebDriver版本必须与 Edge 浏览器版本完全一致(前三位主版本号必须相同)
- 2.3 第一个自动化脚本
- 导入WebDriver:
from selenium import webdriver - 初始化浏览器驱动:
driver = webdriver.Chrome()或webdriver.Firefox() - 打开网页:
driver.get("https://www.example.com") - 获取页面标题:
driver.title - 关闭浏览器:
driver.quit()(完全退出) 与driver.close()(关闭当前标签页)。
- 导入WebDriver:
三、 WebDriver 核心API (定位与交互)
- 3.1 定位页面元素 (Locators) - 八种核心方法
- 通过ID:
find_element(By.ID, “id”) - 通过Name:
find_element(By.NAME, “name”) - 通过Class Name:
find_element(By.CLASS_NAME, “class”) - 通过Tag Name:
find_element(By.TAG_NAME, “tag”) - 通过链接文本:
find_element(By.LINK_TEXT, “完整链接文本”) - 通过部分链接文本:
find_element(By.PARTIAL_LINK_TEXT, “部分链接文本”) - 通过CSS选择器:
find_element(By.CSS_SELECTOR, “css_selector”)(灵活、高效) - 通过XPath:
find_element(By.XPATH, “xpath_expression”)(功能最强大)
详细关于Xpath定位
- 概念:XPath(XML Path Language)是一种在 XML 文档中查找信息的语言,在 Selenium 中用于精确定位 Web 元素
- XPath 类型
- 绝对路径 XPath:从根节点开始的完整路径,以 /开头,示例:/html/body/div/div[2]/form/input,缺点是路径较长,易受页面结构变化影响,维护成本高
- 相对路径 XPath:从当前节点开始,以 //开头,示例://input[@id=’username’]
可以在浏览器页面点击检查元素后,copy该元素的Xpath绝对路径和相对路径:
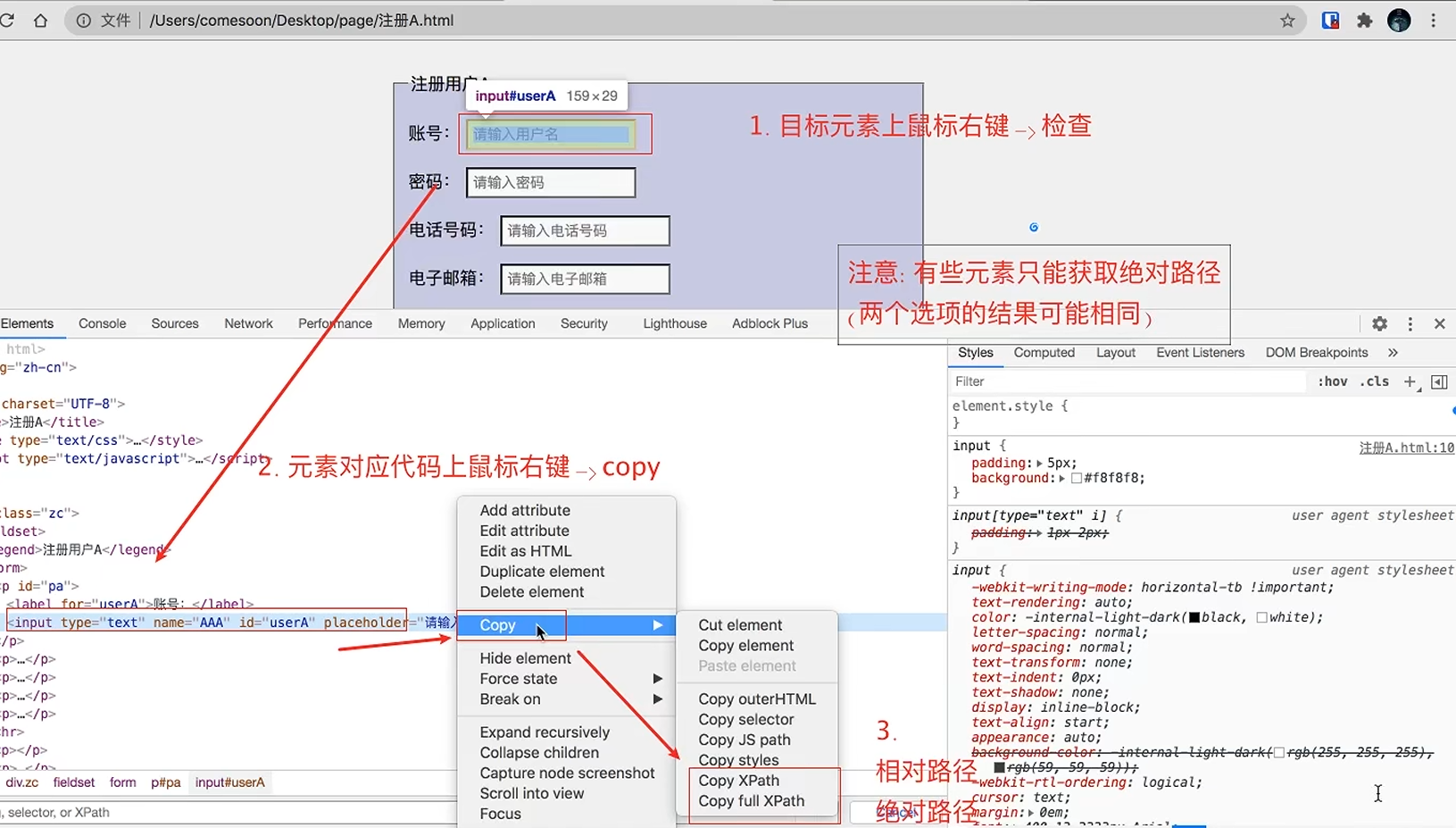
- 基本定位语法
- 按标签名定位
# 所有 input 元素 driver.find_element(By.XPATH, "//input") # 特定位置的 div driver.find_element(By.XPATH, "//div[3]") - 按属性定位
# 通过 id driver.find_element(By.XPATH, "//*[@id='username']") # 通过 class driver.find_element(By.XPATH, "//*[@class='form-input']") # 通过 name driver.find_element(By.XPATH, "//input[@name='email']") # 通过 type driver.find_element(By.XPATH, "//input[@type='submit']") # 多个属性组合 driver.find_element(By.XPATH, "//input[@type='text' and @name='search']") - 按文本内容定位
# 精确文本匹配 driver.find_element(By.XPATH, "//button[text()='登录']") # 文本包含 driver.find_element(By.XPATH, "//a[contains(text(),'忘记密码')]") # 文本开头匹配 driver.find_element(By.XPATH, "//label[starts-with(text(),'用户')]")
- 按标签名定位
- 高级定位技巧
- 使用轴(Axes)定位
# 父节点 driver.find_element(By.XPATH, "//input[@id='child']/parent::div") # 子节点 driver.find_element(By.XPATH, "//div[@class='container']/child::input") # 祖先节点 driver.find_element(By.XPATH, "//span/ancestor::div[@class='wrapper']") # 后代节点 driver.find_element(By.XPATH, "//form/descendant::input") # 紧跟的兄弟节点 driver.find_element(By.XPATH, "//label[@for='email']/following-sibling::input") # 前面的兄弟节点 driver.find_element(By.XPATH, "//input[@type='submit']/preceding-sibling::button") # 所有后续兄弟节点 driver.find_element(By.XPATH, "//h2/following::p[1]") - 位置和索引
# 第一个匹配元素 driver.find_element(By.XPATH, "(//input)[1]") # 最后一个匹配元素 driver.find_element(By.XPATH, "(//li)[last()]") # 倒数第二个 driver.find_element(By.XPATH, "(//div)[last()-1]") # 位置范围 driver.find_element(By.XPATH, "//tr[position()>1 and position()<5]")
- 使用轴(Axes)定位
- XPath 函数
- 字符串函数
# contains() - 包含 driver.find_element(By.XPATH, "//*[contains(@class, 'btn-primary')]") # starts-with() - 开头匹配 driver.find_element(By.XPATH, "//input[starts-with(@id, 'user_')]") # ends-with() - 结尾匹配(XPath 2.0,部分浏览器支持) driver.find_element(By.XPATH, "//input[ends-with(@id, '_input')]") # normalize-space() - 去除首尾空格 driver.find_element(By.XPATH, "//span[normalize-space(text())='保存']") # substring() - 子字符串 driver.find_element(By.XPATH, "//*[substring(@id, 1, 4)='test']") - 逻辑函数
# and 运算符 driver.find_element(By.XPATH, "//input[@type='text' and @name='q']") # or 运算符 driver.find_element(By.XPATH, "//input[@type='text' or @type='search']") # not() 函数 driver.find_element(By.XPATH, "//input[not(@disabled)]")
- 字符串函数
- 实战示例
- 复杂定位场景
# 定位表格中特定行 row = driver.find_element(By.XPATH, "//table[@id='dataTable']//tr[td[2][text()='张三']]") # 动态 ID 处理 element = driver.find_element(By.XPATH, "//div[starts-with(@id, 'result_') and contains(@id, '_container')]") # 表单联动定位 email_input = driver.find_element(By.XPATH, "//label[text()='电子邮箱:']/following-sibling::div//input") # 模态框中的确定按钮 confirm_btn = driver.find_element(By.XPATH, "//div[contains(@class,'modal')]//button[text()='确定']") - 相对定位组合
# 从已知元素相对定位 base_element = driver.find_element(By.ID, "sidebar") target = base_element.find_element(By.XPATH, ".//ul/li[a[contains(text(),'设置')]]/following-sibling::li")
- 复杂定位场景
find_element(返回单个元素) vsfind_elements(返回列表)。
不同定位方式对比
定位方式 优点 缺点 适用场景 XPath 1. 功能最强大,支持轴定位、函数、逻辑运算等复杂查询。
2. 可遍历DOM树(父子、兄弟节点)。
3. 几乎可定位任何属性或文本组合的元素。
4. 浏览器开发者工具支持直接复制和测试。1. 执行速度相对较慢(需解析整个DOM)。
2. 语法相对复杂,编写不当可读性差。
3. 绝对路径脆弱,难以维护。1. 元素无唯一ID或Name时。
2. 需要根据文本内容定位。
3. 需要相对关系(如父子、兄弟)定位。
4. 处理复杂、动态结构的页面。CSS Selector 1. 执行速度通常快于XPath(浏览器原生优化)。
2. 语法简洁、易读,类似jQuery选择器。
3. 对class、id、属性选择非常高效。1. 功能弱于XPath,不支持按文本定位、轴定位受限。
2. 部分浏览器(旧版IE)支持不完全。1. 元素有明确的id、class或属性时首选。
2. 追求高性能的定位场景。
3. 结构简单,无需复杂DOM遍历。ID 1. 速度最快,浏览器有专门优化。
2. 唯一性最好(规范下ID应页面唯一)。
3. 语法最简单。1. 完全依赖开发人员为元素添加唯一且静态的ID。
2. 遇到动态ID(含随机字符串)时不可用。元素有唯一、静态ID时的首选方案,最可靠高效。 Name 1. 速度接近ID定位,非常快。
2. 常用于表单元素,语义清晰。1. 不保证页面唯一,可能返回多个元素。
2. 并非所有元素都有name属性。定位表单元素(input, select, textarea)时的常用方式。 ClassName 1. 速度较快。
2. 适合定位具有相同样式类的一组元素。1. 类名通常不唯一。
2. 元素可能有多个类(复合类),需完全匹配整个字符串。定位具有特定样式类的元素,或批量获取同类元素。 TagName 1. 速度极快。
2. 用于获取特定类型的所有元素。1. 通常返回多个元素,需进一步过滤。
2. 定位非常不精确。快速获取页面所有链接( a)、所有图片(img)等场景。Link Text 1. 专用于超链接( <a>标签),语义明确。
2. 定位精确。1. 仅适用于 <a>标签。
2. 必须完全匹配可见链接文本。需要精确点击某个已知完整文字的超链接时。 Partial Link Text 1. 专用于超链接。
2. 支持部分文本匹配,更灵活。1. 仅适用于 <a>标签。
2. 可能匹配到多个相似链接,需注意唯一性。链接文本较长或部分文本是固定关键字时使用。 注意:selenium3到selenium4的元素定位语法有变化,旧版selenium3的语法现已弃用,使用新语法前先导包:
from selenium.webdriver.common.by import By详情关于语法变化
Selenium 3(旧语法) Selenium 4(新语法) driver.find_element_by_id("id")driver.find_element(By.ID, "id")driver.find_element_by_name("name")driver.find_element(By.NAME, "name")driver.find_element_by_class_name("class")driver.find_element(By.CLASS_NAME, "class")driver.find_element_by_tag_name("tag")driver.find_element(By.TAG_NAME, "tag")driver.find_element_by_link_text("text")driver.find_element(By.LINK_TEXT, "text")driver.find_element_by_partial_link_text("text")driver.find_element(By.PARTIAL_LINK_TEXT, "text")driver.find_element_by_xpath("xpath")driver.find_element(By.XPATH, "xpath")driver.find_element_by_css_selector("selector")driver.find_element(By.CSS_SELECTOR, "selector")对应的查找多个元素方法:
find_elements_by_*()→ find_elements(By.*, value) - 通过ID:
- 3.2 元素基本操作
- 输入文本:
element.send_keys(“text”) - 点击:
element.click() - 清空内容:
element.clear() - 获取元素属性/文本:
element.get_attribute(“attr”),element.text - 判断元素状态:
element.is_displayed(),element.is_enabled(),element.is_selected()
- 输入文本:
- 3.3 浏览器窗口与导航控制
- 控制浏览器大小:
driver.maximize_window(),driver.set_window_size(width, height) - 浏览器导航:
driver.back(),driver.forward(),driver.refresh() - 获取当前URL和标题:
driver.current_url,driver.title
- 控制浏览器大小:
- 3.4 下拉框 (Select)、单选框 (Radio)、复选框 (Checkbox)
- Select:
from selenium.webdriver.support.select import SelectSelect(element).select_by_index/visible_text/value(...)Select(element).deselect_all(),Select(element).options
- Radio & Checkbox:通过
click()操作改变状态。
- Select:
四、 高级交互与复杂场景处理
- 4.1 等待机制 (Waits) - 处理页面异步加载
- 强制等待:
time.sleep(seconds)(不推荐,除非调试)。 - 隐式等待 (Implicit Wait):
driver.implicitly_wait(seconds),全局设置,在查找元素时生效。 - 显式等待 (Explicit Wait):最佳实践。
from selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as EC- 用法:
WebDriverWait(driver, timeout).until(EC.条件(定位器)) - 常用条件:
presence_of_element_located,visibility_of_element_located,element_to_be_clickable,title_contains
详情关于显式等待
- 核心机制
from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By # 基本结构 wait = WebDriverWait(driver, timeout=10, poll_frequency=0.5, ignored_exceptions=None) element = wait.until(EC.presence_of_element_located((By.ID, "dynamic-element")))参数解析:
driver:WebDriver 实例
timeout:最长等待时间(秒)
poll_frequency:轮询间隔(秒),默认 0.5
ignored_exceptions:轮询期间忽略的异常列表,默认只忽略 NotFoundException - Expected Conditions 条件详解
Selenium 4 中的 ExpectedConditions(注意:Selenium 4 将部分常用条件移入新位置):
# Selenium 4 推荐导入方式 from selenium.webdriver.support.expected_conditions import * # 常用等待条件分类: # 1. 元素存在性 element = wait.until(presence_of_element_located((By.ID, "element-id"))) # 仅要求元素存在于DOM中,无论是否可见 # 2. 元素可见性 element = wait.until(visibility_of_element_located((By.ID, "element-id"))) # 元素存在且可见(display != none, visibility != hidden, opacity > 0, width/height > 0) # 3. 元素可交互性 element = wait.until(element_to_be_clickable((By.ID, "button-id"))) # 元素可见且启用(enabled) # 4. 元素文本内容 element = wait.until(text_to_be_present_in_element((By.ID, "status"), "加载完成")) # 元素包含指定文本 # 5. 元素属性值 wait.until(text_to_be_present_in_element_value((By.ID, "input"), "expected_value")) # 6. 元素被选中(复选框/单选框) wait.until(element_to_be_selected((By.ID, "checkbox"))) # 7. 多元素条件 elements = wait.until(presence_of_all_elements_located((By.CLASS_NAME, "item"))) # 至少找到一个元素 wait.until(visibility_of_any_elements_located((By.CLASS_NAME, "item"))) # 至少一个元素可见 # 8. 框架/窗口条件 wait.until(frame_to_be_available_and_switch_to_it((By.ID, "iframe-id"))) # 切换到可用框架 wait.until(number_of_windows_to_be(2)) # 等待窗口数量变为2 - 自定义等待条件
# 通过lambda表达式创建复杂条件 wait.until(lambda d: d.find_element(By.ID, "progress").get_attribute("value") == "100") # 自定义条件类 class element_has_css_class: def __init__(self, locator, css_class): self.locator = locator self.css_class = css_class def __call__(self, driver): element = driver.find_element(*self.locator) if self.css_class in element.get_attribute("class").split(): return element return False wait.until(element_has_css_class((By.ID, "status"), "active")) - 复合条件与否定条件
# 使用逻辑运算符组合条件 from selenium.webdriver.support.expected_conditions import all_of, any_of, none_of # 所有条件都满足 wait.until(all_of( visibility_of_element_located((By.ID, "element1")), element_to_be_clickable((By.ID, "element2")) )) # 任一条件满足 wait.until(any_of( presence_of_element_located((By.ID, "alt1")), presence_of_element_located((By.ID, "alt2")) )) # 条件不满足 wait.until(not_(visibility_of_element_located((By.ID, "loading"))))
- 强制等待:
- 4.2 处理弹窗/警告框 (Alerts)
- 切换到Alert:
alert = driver.switch_to.alert - 操作:
alert.accept()(确认),alert.dismiss()(取消),alert.send_keys(),alert.text(获取弹窗文本)
- 切换到Alert:
- 4.3 处理多窗口和框架/Iframe
- 多窗口/标签页:
- 获取所有窗口句柄:
driver.window_handles - 切换窗口:
driver.switch_to.window(handle_name)
- 获取所有窗口句柄:
- 框架/Iframe:
- 切换到iframe:
driver.switch_to.frame(frame_reference)(可通过id/name/index/元素) - 切换回主文档:
driver.switch_to.default_content() - 切换回父框架:
driver.switch_to.parent_frame()
- 切换到iframe:
- 多窗口/标签页:
- 4.4 鼠标与键盘高级操作 (ActionChains)
from selenium.webdriver.common.action_chains import ActionChains- 常用操作:
click(),double_click(),context_click()(右键),drag_and_drop(source, target),move_to_element()(悬停),send_keys()。 - 链式调用:
ActionChains(driver).move_to_element(menu).click(submenu).perform()
- 4.5 执行JavaScript代码
driver.execute_script(“javascript code”)- 用途:修改元素属性、滚动页面、处理特殊元素、执行异步操作。
- 4.6 文件上传与下载
- 上传:对于
<input type=”file”>元素,直接使用send_keys(“文件完整路径”)。 - 下载:设置浏览器下载选项(如ChromeOptions指定下载路径,禁用下载弹窗)。
- 上传:对于
- 4.7 网页截图/元素截图
- 网页截图:使用driver.save_screenshot()或driver.get_screenshot_as_png(),作用一样,后者返回一个boolean值
- 元素截图:直接使用element.screenshot()
from selenium import webdriver driver = webdriver.Chrome() driver.get("https://www.example.com") # 保存截图到指定路径 driver.save_screenshot("screenshot.png") # 与save_screenshot类似,但返回布尔值表示是否成功 result = driver.get_screenshot_as_file("screenshot.png") print(f"截图是否成功: {result}") # True/False # Selenium 4+ 可以直接调用元素的截图方法 element = driver.find_element("id", "logo") # 方法一:保存到文件 element.screenshot("logo.png")
五、 测试框架集成与最佳实践
- 5.1 与单元测试框架集成 (以Python为例)
- unittest:Python标准库,内置
setUp/tearDown。 - pytest:主流选择,更灵活强大。
- 使用fixture管理driver生命周期:
@pytest.fixture(scope=”class”) - 插件:
pytest-html(生成报告),pytest-xdist(并行执行)。
- 使用fixture管理driver生命周期:
- unittest:Python标准库,内置
- 5.2 数据驱动测试
- 概念:将测试数据与测试逻辑分离。
- 实现:使用
@pytest.mark.parametrize装饰器,或从JSON、Excel、CSV、YAML文件中读取数据。
- 5.3 Page Object Model (POM) 设计模式
- 核心思想:将页面抽象为类,页面元素作为属性,页面操作作为方法。
- 优点:提高代码可维护性、复用性,降低耦合。
- 基本结构:
BasePage(基类,封装公共方法) ->LoginPage,HomePage(具体页面类)。
- 5.4 日志与报告生成
- 使用Python
logging模块记录执行过程。 - 生成HTML测试报告:
pytest-html插件,Allure框架。
- 使用Python
六、 高级主题与扩展
- 6.1 Selenium Grid 配置与使用
- Hub与Node的架构。
- 启动Hub和Node。
- 编写脚本连接远程Grid,实现多环境并行测试。
- 6.2 浏览器选项与功能 (Options)
ChromeOptions/FirefoxOptions:无头模式、禁止图片加载、设置代理、添加扩展、设置用户数据目录、设置下载路径等。
- 6.3 无头浏览器模式 (Headless)
- 目的:在不打开GUI的情况下运行,节省资源,适用于CI/CD。
- 设置:
options.add_argument(“--headless”)或options.headless = True。
- 6.4 处理验证码
- 策略:禁用(测试环境)、延迟手动输入、接入第三方OCR服务(复杂且不稳定)、与开发约定万能验证码。
- 6.5 性能与稳定性优化
- 使用显式等待代替强制等待和过长的隐式等待。
- 优化定位器,优先使用稳定的ID、CSS Selector。
- 合理使用
ActionChains和JavaScript。 - 管理Driver生命周期,确保
quit()被调用。
七、 实战与常见应用场景
- 7.1 自动化测试
- 端到端 (E2E) 测试流程。
- 编写健壮、可维护的测试用例。
- 7.2 网页数据爬取
- 与Scrapy、BeautifulSoup结合(Selenium处理动态加载,Soup解析静态内容)。
- 处理无限滚动、登录会话。
详情关于cookie绕过登录
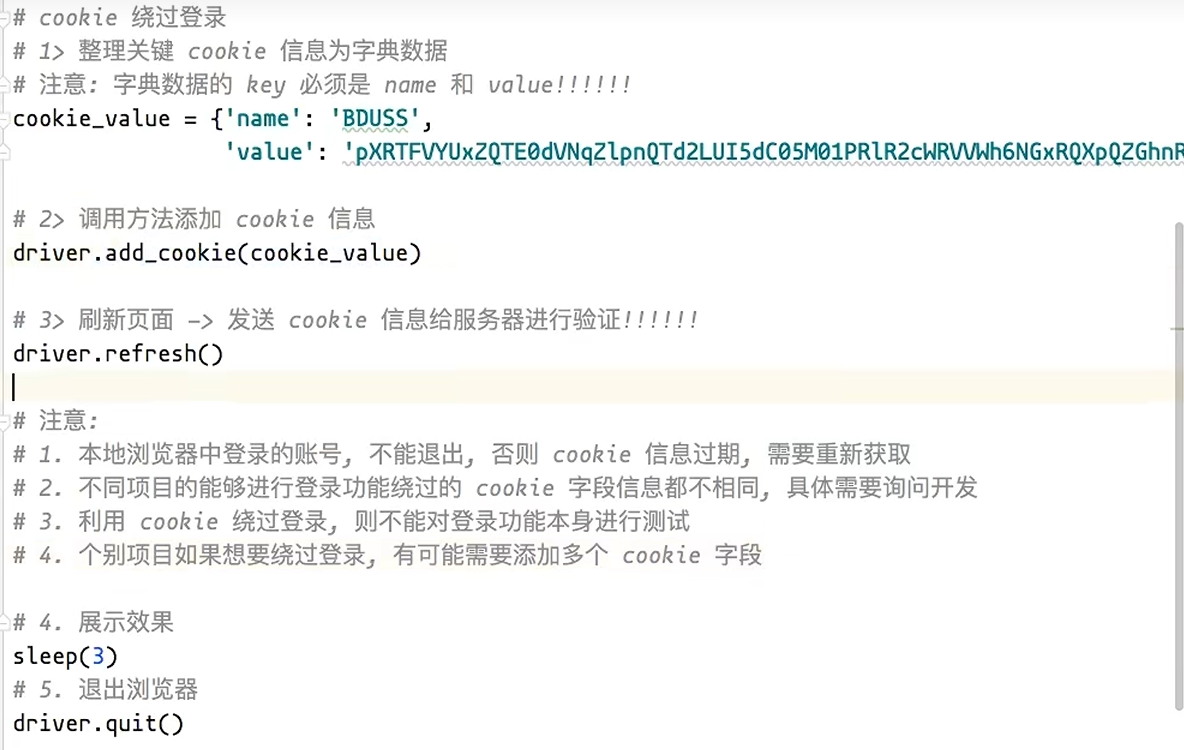
- 7.3 日常办公/网页自动化
- 自动化填表、重复性网页操作。
- 7.4 学习路径建议
- 阶段1:掌握环境搭建、核心API、元素定位与基本交互。
- 阶段2:精通高级交互(等待、弹窗、多窗口、ActionChains)。
- 阶段3:集成测试框架 (Pytest),实践POM设计模式。
- 阶段4:学习Selenium Grid、高级配置,并应用于CI/CD。
八、 资源与社区
- 8.1 官方文档
- Selenium官方文档: https://www.selenium.dev/documentation/
- 浏览器驱动官方地址。
- 8.2 社区与教程
- Stack Overflow (解决问题)。
- 官方Selenium GitHub仓库与Issue。
- 8.3 练习网站
- http://the-internet.herokuapp.com/ (经典练习场)
- 各大电商网站登录、搜索、下单流程(用于复杂场景练习)。
- 8.4 项目实践想法
- 为个人博客或开源项目编写一套E2E UI测试用例。
- 编写一个自动化脚本,每天从特定新闻网站抓取头条新闻并发送邮件。
- 模拟完成一个Web应用的完整业务流程(如用户注册-登录-添加商品到购物车-下单)。